
 手机端
手机端

7月21日,在游戏开发者大会(GDC)的分享会上,来自网易伏羲AI实验室人工智能专家, 虚拟人团队负责人丁彧分享了网易伏羲在游戏场景中动画合成方面的AI算法。
网易伏羲实验室在人工智能领域积极探索,推出了游戏行业人工智能解决方案,横跨AI反外挂、AI竞技机器人、AI 对战匹配以及 AI 剧情动画制作四大AI能力,实现了AI 技术在游戏行业的新突破。本次分享的内容就是源于AI剧情动画制作在游戏中的运用经验
以下为分享实录:
大家好,我是丁彧,来自网易伏羲人工智能实验室,非常高兴有机会介绍我们在游戏场景中动画合成方面的工作,更具体来说,我们的动画合成聚焦在虚拟角色在说话表达时的面部表情动画参数合成算法。
现在,让我们一起来分析下问题的背景和解决问题的思路。
首先,我们一起来观察游戏应用中,已存在的动画参数制作方法和限制。传统方法中,动画参数依赖于经验丰富的动画师手动制作完成。一般来说,一段时长10秒的动画通常需要两天甚至一周的时间才能够完成,更为精细的动画,需要更长的手动制作时间。 近些年来,随着动作捕捉技术的发展,制作一条10秒的动画依然需要半天时间,包括数据捕捉和手动矫正。总体来说,手动制作和动画捕捉都非常耗时。聘用经验丰富的动画师和建立动作捕捉系统经济成本都非常高。更为值得关注的是,手动或动捕制作的动画数据仅仅能应用于特定的剧情,复用性差。这些原因就导致了玩家经常看到的动画片段重复使用,损失了动画数据对剧情的匹配性,同时又缺乏了动画的多样性。

此外,使用手动和动捕动画数据过程中,如何拼接两段动画数据一直是一个难题。通常情况下,动画工程师们选择一个插值函数去完成拼接的功能。本质来说,一个插值函数总是能够在部分动画数据拼接上表现很好,但又同时在其他的数据拼接上失败,性能欠佳。这主要是因为插值函数定义了一种固定的模式去补全需要插值的信息,如果待拼接的数据正好符合插值函数定义的模式,那么效果就会很好,另一方面,还存在大量待拼接的数据是不符合插值函数定义的模式,这种情况下,插值函数就无法补全有效的信息,插值后动画数据缺乏自然性和真实性,特别是高频细节信息。
观察以上提到的动画参数制作方法和它们的限制,我们AI从业人员提出一个问题,是否有可能自动生成动画参数。具体而言,我们今天汇报的工作聚焦在说话状态下虚拟角色表情动画参数的合成算法。针对这个课题,我们的目标是降低动画参数合成的时间成本,同时我们也致力于生成高质量的动画参数。何为高质量的动画参数呢?高质量的动画参数应该是自然的、生动的,类人的。生成的动画参数能够传递恰当的情绪和意图,同时它们也应该是多样化的,而不应该是重复性的。

在我们当前的工作中,一段15秒的表情动画自动合成少于60毫秒,一段20秒的肢体动画生成时间低于600毫秒。我们的工作已经应用于网易开发的多款游戏和在线教育产品。
现在让我们一起来思考下,当我们说话的时候,针对我们的行为,究竟发生了什么?事实上,大量的科研学者已经报道了我们的行为能够强调我们表达的想法,也反映了说话的韵律节奏,补充了语义信息,同步也传递了表达意图和交流意图。也就说,说话的过程中,人的表情行为是与同步说话的语音和说话内容紧密相关。正是这一点,启发我们思考,基于语音和行为的时序关系,如何根据同步的说话语音数据,生成动画参数。
为了完成以上的目标,我们的解决思路是采用深度神经网络来实现语音到动画参数的映射,采用神经网络学习和捕捉人类行为和语言之间的时序相关性。在动画参数合成阶段,神经网络使用语音作为输入,生成动画时序参数。在该阶段,神经网络能够把其学习到的时序关系注入到生成的动画数据中,这样生成的动画数据就能够反映出同步语音的韵律节奏,甚至是语义信息。
总所周知,神经网络训练需要大量的数据。为了获得充足的数据,我们使用了vicon光学动画捕捉系统用于捕捉身体动画,使用dynamixyz用于捕捉面部表情。在我们的工作中,嘴唇和下颚(嘴唇区域)每帧的动作由28维向量表征,眼皮和眉毛由22维向量表征,身体由76维身体向量表征。动作捕捉方式确保了较高质量的原始数据。为了获得更高质量的数据,我们手动完成面部和身体的重定向,以便降低录制数据演员和目标虚拟角色之间的骨骼和面部差异带来的误差。
训练数据由大量配对同步的语音、表情和肢体动画组成。每一个配对都对应一个句子。方便起见,我们用T表示语音长度(帧数)。下半面部表情由持续T帧的28维动画序列表示;上半面部表情由持续T帧的23维动画序列表示;身体动画则由持续T帧的76维动画序列表示。由于下半面部、上半面部和身体与语音有着不同的时序关系,因此,我们的算法分为独立的三个神经网络,分别完成下半面部、上半面部和身体部分的动画参数合成。
现在,我们一起来聊聊下半面部表情参数动画合成算法,涉及到嘴唇和下颚的动画。应该不少听众可能都会比较熟悉这个课题。观察大多数已发表的论文,语音特征经常被用作输入,输出嘴唇区域的动画参数。当然,语音特征确实包括了全部的语音信息。但是,另一方面,语音特征保留了一些与动画不相关的信息。比如,特定于说话人的音色信息就包括在语音中,可是,音色信息并不能包含任何与动画参数相关的信息。如果语音特征受到特定说话人音色的干扰,那么这些语音特征也一定会损害生成动画的质量。当然,我们也可以试问我们是否能够使用已剔除或与音色无关的语音特征呢?非常不幸,绝对与音色无关的语音特征提取非常困难。其实,我们也一直在努力获得与音色解耦合的语音特征。
为了规避音色等不必要因素的影响,我们没有采用语音特征,转而使用其他有效的特征。我们提出采用文本特征用于嘴唇动画合成,具体来说,就是发音的内容,音素。音素就是绝对意义上与说话人无关的信息。它也非常容易获得。对于真实语音,使用语音识别工具即可获得;对于合成语音,音素可以从语音合成器中直接获得。
这里,我再着重强调一个细节。一旦我们从语音中提取到音素序列,根据音素持续的时间,我们可以获得时序对齐的音素。操作层面上,根据音素持续的时间,我们重复音素标签,如图所示,我们就能够得到时序对齐的音素序列。为了方便计算,我们将这个音素序列的频率设置为与动画序列的频率一致。这张幻灯片展示了一个例子“oh yeah, you don’t want to tell me where she is”。根据语音信号,语音识别工具可以输出时序对齐的音素序列。就像幻灯片中观察到的一样,音素按照它们持续的时间重复对齐排列。

之前也提到过,神经网络用来提取音素和动画参数的时序关系。一般来说,我们会考虑使用LSTM,长短记忆网络。它是一种典型用来模拟时序关系的神经网络。事实上,大量的学者都已经尝试使用过LSTM处理时序关系,并且有着大量成功的实验结果。另一方面,值得注意的是,LSTM是一个递归神经网络,它逐帧输出时间序列。下一帧的输出依赖于前些帧的输出。这样一个递归的计算模式导致计算过程非常耗时。因此,我们尝试使用另一个神经网络结构,卷积神经网络,CNN。CNN通过并行计算完成时间序列的输出。在我们的实验中,对于一段15秒的序列来说,LSTM花费500至800毫秒,然而,CNN只需花费20至60毫秒。

这张幻灯片展示了具体的神经网络结构,输入是一段时序对齐的音素序列。我们方法采用了12层神经网络,每一层都是一残差层。它的输出是持续T帧的28维动画参数序列。在我们的实验中,T取30。训练数据包含865句样本,每一句都持续5至15秒。

这张幻灯片显示了四组对照的视频,每组视频由一对虚拟角色视频组成,它们展示同一个角色说同样的话,但是驱动它们的动画参数不一样,左边视频中的虚拟角色由神经网络算法合成的动画参数驱动,右边视频中的虚拟人角色由动捕数据驱动。可以观察到每组视频中左右虚拟角色展示的表情动画参数都非常接近,这就意味着神经网络算法有能力合成高质量的表情动画参数。
进一步,我们也尝试将嘴唇区域动画合成算法扩展到没有预定义三维角色模型的二维像素级说话人脸视频合成中,该工作也发表在AAAI2021,题目为write-a-speaker: text-based emotional and rhythmic talking-head generation。这段视频依然展示了一组视频,左边人物展示了由以上介绍算法合成的效果,右边是由相机录制的真实说话人视频。我们可以观察到算法在二维视频效果中,依然展示了高质量的效果。

接下来,我们谈谈上半部脸表情合成的工作,具体是涉及了眉毛和眼皮的动作。类似于嘴唇区域的动画生成,我在这里重复两个应该注意的问题,一个是使用时序对齐的说话文本信息,而不是语音信号。这里,我们也强调有别于下半脸部使用时序对齐的音素,上半部脸表情动画合成使用时序对齐的文字(说话内容)信号。
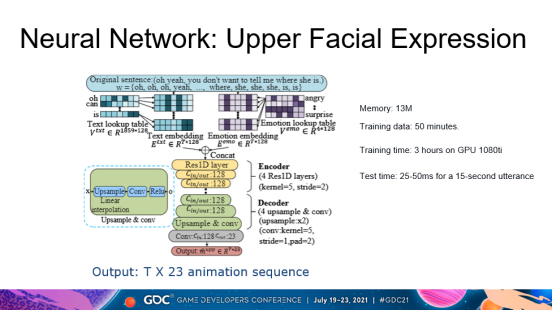
这张幻灯片显示了上半部脸面部表情的神经网络结构。输入是时序对齐的文本序列,输出是持续时间T帧的23维动画序列。这个神经网络是一个典型的编码-解码网络结构。在图中,编码器由黄色标记,解码器由绿色标记。编码器从文本信号中提取有意义的信息,并由一隐层编码表示,然后再由解码器将隐层编码转换/解码成输出的动画参数序列。训练集由50分钟有效数据构成。
现在,我重复四组对照视频,这次让我们关注眉眼区域,可以观察到左右视频展示的动画参数非常接近。这就意味着我们的算法是有效的,能够生成合理的、自然的动画参数。
这里,我展示一段来自网易出品游戏《逆水寒》中的片段,其中表情就是由以上介绍的算法生成得到。

再展示一段来自网易出品的另一款游戏《天谕》中的片段,其中表情也是由以上介绍的算法生成得到。

可以看到,我们的工作展示了AI能够帮助动画参数合成。一段10秒的动画序列能够自动在60毫秒内生成,而不再需要花费数天的手动制作。

总体来说,我们的工作说明了以下几个方面:1)说话状态下,同步的动画和语音之间存在着相关性,表情行为同步与说话内容和语音韵律节奏;2)深度学习技术能够建立人类表情行为和同步语音之间的相关性,并能够根据语音信号,自动生成表情行为动画参数;3)依赖于深度学习技术,针对一句话,表情行为动画参数生成可以低于60毫秒。

当然,我们的工作也存在一些缺陷和不足:1)生成更富有表达能力的动画还需要同行从业者们很多的努力;2)重定向问题依然没有得到高质量的解决,依然困扰着动画输出质量;3)训练有效的神经网络依赖于高质量的动捕数据,如何降低数据采集的经济和时间成本依然是值得研究的问题;4)动画风格仅取决于录制的数据,如何提高风格的泛化性,减少数据采集量,依然具有现实意义。
在将来的工作中,我们会关注如何同时使用文本和语音信号,从而生成更富有表达能力的动画参数,另一个问题,我们至今还未解决的是,如何在一个神经网络框架下同步处理多模态动画,同时,一个可能长期存在,非常值得我们努力的方向是,如何生成更富有语义信息的面部表情和肢体动画参数。
演讲者简介
丁彧 网易伏羲AI实验室人工智能专家, 虚拟人团队负责人,专注于智能虚拟人研究及落地工作10余年,发表论文40余篇(包括中国计算机学会A类会议CHI、CVPR、AAAI、IJCAI、ACMMM)。获ICCV2021人脸表情国际挑战赛(ABAW)“人脸表情动作单元检测”冠军、“情绪识别”冠军、和“愉悦度-唤醒度评估”亚军。负责研发了领先业界的游戏虚拟人物剧情动画合成技术,并载入《(2020)中国虚拟数字人白皮书》;参与起草行业标准《(中国)虚拟数字人指标要求和评估方法》。担任ACM智能虚拟体国际会议(2018-2021)和ACM多模态交互国际会议(2019-2021)程序委员会委员、计算机与教育国际会议组委会主席(2017)、领域主席(2018)和工业主席(2019-2021)。首创“虚拟教师”和“虚拟伴读”应用于网易编程教育产品《极客战记》和网易有道儿童阅读APP《有道阅读》。“虚拟形象代言人”落地应用于政府机构和城市商业中心。

元宇宙数字产业服务平台
下载「陀螺科技」APP,获取前沿深度元宇宙讯息
110777025(手游交流群)
108587679(求职招聘群)
228523944(手游运营群)
128609517(手游发行群)















