
 手机端
手机端

北京时间7月21日,在游戏开发者大会(GDC2021)上,来自网易伏羲的雷子涵分享了在回合制纸牌游戏中应用 AlphaZero 开发AI。
网易伏羲实验室在人工智能领域积极探索,推出了游戏行业人工智能解决方案,横跨AI反外挂、AI竞技机器人、AI 对战匹配以及 AI 剧情动画制作四大AI能力,实现了AI 技术在游戏行业的新突破。本次分享的内容就是源于AI卡牌竞技机器人在游戏中的运用经验。
以下为分享实录:
我们在天谕手游的谕戏游戏中使用了 AlphaZero 来制作 AI。本次演讲主要分为以下4个部分。第一部分介绍AlphaZero的基本思想和核心算法Monte Carlo Tree Search,简称MCTS。第二部分是关于天谕手游中卡牌游戏谕戏的介绍。第三部分介绍我们如何在谕戏上应用alphazero来产生AI。最后展示我们取得的结果和展望未来的工作。
一、AlphaZero 和 MCTS
什么是AlphaZero?
围棋一直被视为人工智能经典游戏中最具挑战性的游戏。但是 AlphaGo 在 2016 年击败了世界冠军李世石。 AlphaGo 是第一个击败围棋人类世界冠军的计算机程序,可以说是当时最强的围棋选手。
AlphaGo有如此高的成就和荣誉,那AlphaZero为什么会诞生呢?
因为在阶段性训练和网络数量方面,AlphaGo 的系统相当复杂。一年后,其作者 DeepMind 对其进行了改进,提出了一种新的围棋 AI: AlphaGo Zero,它是 AlphaGo 的简化和增强版本。由于算法的通用性和围棋知识较少,DeepMind 又将算法迁移到国际象棋和日本将棋,并推出了新的 AI:AlphaZero。

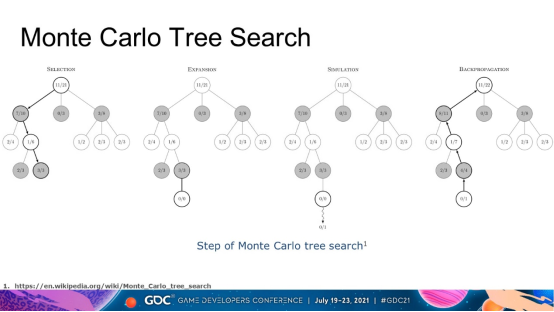
简单说完alpha系列的演化,我们来看看它的算法。由于算法细节繁琐复杂,这里只做简单的科普。AlphaGo的核心算法为蒙特卡罗树搜索与改进。蒙特卡罗树搜索是算法的核心。它主要通过使用随机抽样来解决确定性问题。 如下图所示,分为选择,扩展,模拟与反向传播4个步骤。每当我们需要做决策时,我们都可以通过这棵树得到蒙特卡洛算法下的最优策略。当然,它不一定是真正的最优策略。
原本的 MCTS 看起来很笨,而且计算量很大。 AlphaGo 对其进行了很多改进。它使用深度神经网络进行评估而不是随机搜索来评估情况,如下图所示,Alphago中有3个神经网络;同时,DeepMind 还提出了 PUCT 算法,引入了神经网络的直觉,引导 MCTS 在搜索时进行探索,大大提高了搜索效率。由于引入了神经网络,AlphaGo 变得可学习,并且可以通过训练神经网络不断提升自身实力。
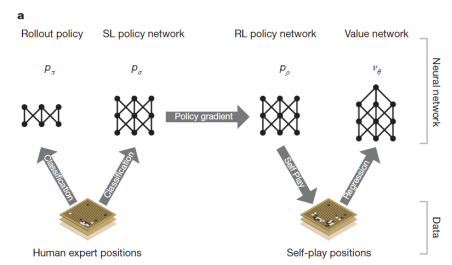
AlphaGo 的训练过程分为两个步骤:
第一步,收集大量人类专家数据进行监督学习,学习人类思维。经过训练,神经网络已经达到了业余水平。
第二步,转化为强化学习。神经网络的数据来自自我对弈。通过不断的强化训练,AlphaGo的水平不断提升,最终达到了超越人类的水平。
2.从AlphaGO到AlphaGo Zero

AlphaGo Zero 不使用人类专家数据进行监督学习。将训练简化为一个阶段,从头开始自我对弈和强化学习。基于内在的变化,AlphaGo Zero 的实力相比 AlphaGo 有了很大的提升,如上图所示。经过3天的学习,零号AlphaGo以100:0的比分超越了AlphaGo Lee的实力,21天后达到了AlphaGo Master的水平,并在40天内超越了之前的所有版本。
二、谕戏介绍

天谕手游是网易游戏开发的一款大型多人在线角色扮演游戏。自2021年1月8日上线以来,它在中国是一款非常成功的游戏。

谕戏是天谕手游中的回合制纸牌玩法,目的是让玩家熟悉世界观背景,放松心情。谕戏的玩法是两个玩家之间的1V1对战。有3种不同大小的棋盘,分别是3乘3、4乘4和6乘4。谕戏有200多张卡片,包括人物卡和法术卡。没有比赛和排行榜。玩家只能选择与 AI 或他们的朋友对战。当玩家需要测试新套牌的强度或者没有朋友可以对战时,我们的AI就会出场。
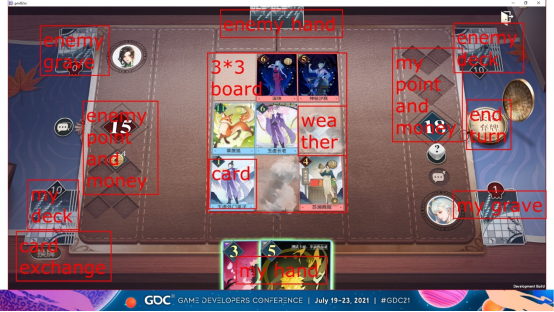
这是游戏中谕戏具体场景的截图,图片信息量很大。
中间是一个3乘3场地。场地上有人物卡和天气。蓝色的代表我们自己的角色,红色的代表敌人的角色。卡的具体信息将在后面详细说明。
左上角和右下角是双方玩家的坟墓。当角色卡死亡或使用法术卡时,他们会进入坟墓。
左下方和右上方是卡组,玩家将带着自己的卡组进入游戏。
上面和下面是手牌,初始手牌是从卡组中随机抽取的(数量根据场地的大小而变化)。
游戏过程类似于巫师的昆特牌。玩家不会每轮都从牌组中抽牌。一般每回合打一张手牌,用完所有手牌后游戏结束。
棋盘两边是2位玩家的点数和金钱,最右边是结束回合按钮。
左下角的换卡按钮,后面会详细说明。

每张卡都有自己的头衔和效果,很多效果都是在一些固定的头衔上触发的。
对于人物卡,左上角也有一个初始点。如果当前点低于初始点,则显示为红色,可被治愈;如果它更高,它将显示为绿色。人物卡还有一些临时的buff标志,比如当前技能可用,这个人物有多少钱等等。
三.AlphaZero在谕戏中的应用
接下来,我们将详细介绍我们是如何在谕戏上应用alphazero来生产AI的。
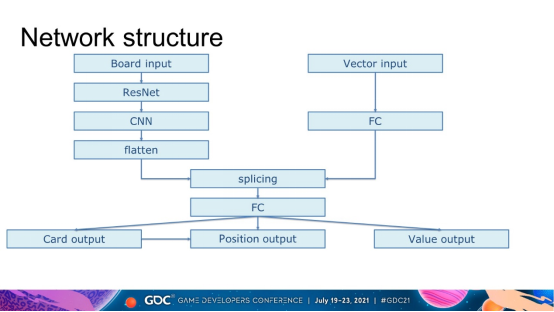
我们使用的深度神经网络的结构如上图所示。输入分为场地输入和向量输入。场地输入主要是场地上的信息。它是一个 3 维张量。在resnet和cnn之后,使用flatten操作将其转化为向量。向量输入通过全连接网络后直接变成向量。然后将两者拼接在一起,通过全连接得到三个输出,分别是当前情况的卡片id、位置和值估计。
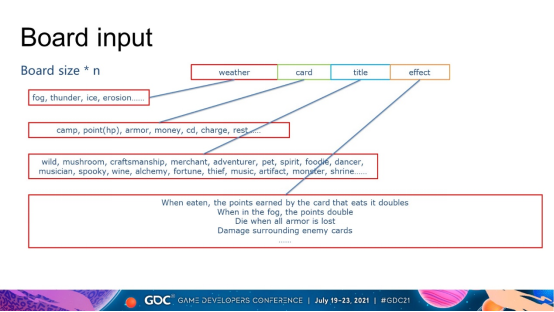
棋盘输入的前 2 个维度是棋盘的大小。例如,3乘3板的输入大小是3乘3乘n。深度 n 是一些人工提取的特征,而不是直接使用卡片 id。这样做的好处是泛化性更好,神经网络更容易学习。这些功能分为 4 类。天气、卡片基本属性、卡片名称和卡片效果。天气包括雾、雷、冰、侵蚀。卡牌基本属性包括阵营、点数、护甲、金钱、技能冷却等。头衔和效果有很多维度,最终总深度在90左右。
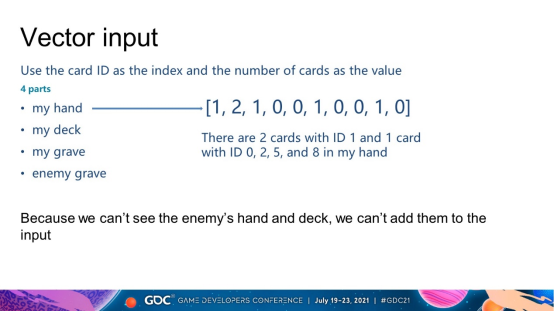
向量输入不使用特征,因为它不如场地输入重要。它直接以卡片的id作为索引,卡片的数量作为值。主要包括4个部分,自己的手牌,牌组,坟墓和敌人的坟墓。敌人的手牌和牌组不作为输入,因为它们是不可见的。我们将这 4 个部分拼接成一个向量作为输入。例如,我手上有 2 张 ID 为 1 的卡和 1 张 ID 分别为 0、2、5 和 8 的卡,如图所示。

输出时,我们使用合法掩码来确保输出动作是合法的。
输出动作主要分为两步。首先,输出卡的id。合法掩码保证这个id必须是手上可以使用的卡片。然后将倒数第二层和选中卡片的id拼接输出合法位置。最后将这张牌打到指定位置。此外,我们还将结束回合按钮编码到卡号中作为卡号0。选择此操作将结束本回合,否则我们将继续出下一张卡。因为谕戏类似于巫师的昆特牌,一般来说每轮最多只能使用一张牌,但由牌产生的衍生牌,这里称为虚空牌,不受此限制。对于神经网络难以处理的不规则的情况,我们使用规则来实现后续的选择。
最后,模型也会输出一个值作为当前情况的估计。

在谕戏中,我们的AI会以NPC的身份与玩家对战,所以使用的套牌是固定的。我们有50多套固定卡组,每个卡组都由一个独特的模型控制。训练时,从游戏中随机抽取2套牌进行对战,可以是相同的。例如,如果第 3 副和第 7 副牌随机对战,它们将分别调用模型 3 和模型 7,并且该游戏的数据将仅用于训练模型 3 和模型 7。
当然,我们同时拥有数千个游戏进行训练。并且我们在训练期间没有使用卡片交换操作。
我们的第一次训练使用了大约 100 个 CPU 和 8 个 GPU,耗时一个月。
之后,更新迭代使用了 50 个 CPU 和 4 个 GPU,耗时一周。
因为在线使用时玩家的出牌速度较慢,所以4个CPU就可以满足要求。

我们知道围棋、国际象棋和将棋是具有完整信息的游戏。在这类游戏中搜索非常容易。但是在不知道对方手牌的情况下在谕戏中搜索呢?
在训练时,我们直接让对手给一个操作,并用这个操作来搜索对手。
比如刚才的模型3对战模型7。现在轮到模型3出牌了,模型3手上有两张id为1和2的牌。它不知道哪个卡更好。因此,模型3先打出一张id为1的牌,然后根据当前情况让模型7出一张牌,然后模型3再打出一张id为2的牌,直到游戏结束。而模型3也可以先是牌2,然后是牌1。以上过程都是模拟搜索。搜索结果可用后,模型 3 根据概率选择更好的策略。这些功能的实现需要依赖一个可以生成和加载快照的游戏环境。在线时,我们不搜索手牌,因为我们不能让对手采取行动。这也是上网时资源占用少的原因。
但是我们会搜索换卡。在每一轮中,都有机会将手牌与牌组中的两张牌中的一张交换。

因为换卡只和自己有关,所以我们可以遍历它所有可能的结果。然后将其输入网络,只取值输出,选择换卡操作后值最大的结果。
三、我们的成就和未来的工作
我们来看一场对抗AI的游戏。在这个游戏中,AI可以巧妙地利用螃蟹的效果互相吃掉,积分翻倍。

在游戏开发过程中训练AI不仅可以发现一些会报错的bug,还可以发现设计的bug。如以上两张图片所示。左边的一张牌具有可以回收3个棋盘上的钱币并转化为手牌的效果。另一张卡的效果是使用钱币时少使用2个钱币。但是我们发现了一个神奇的BUG,回收币也出现了少用两个币的效果。结果,棋盘上只有一枚钱币,却拿到了三张钱币卡。
右图是一张牌在雾中吃另一张牌的结果。雾的效果是卡点减半。然后我们的新卡一放下就从6分减半到3分。然后在迷雾中吃掉8分的牌,得到11分。但正确的情况是先吃到14点,减半到7点。

不仅能发现BUG,我们的 AI 还可以帮助开发人员实现游戏平衡。在游戏结束时,第一个玩家将随机获得一个骰子的奖励积分。经过AI训练,我们发现3乘3场地的先手玩家有优势,但在6乘4场地有劣势。所以以后我们在游戏中创建谕戏房间的时候,可以设置一个规则来取消这个骰子奖励。
我们上线后,AI的调用量一直处于较高水平。AI刚开始的时候胜率是60多,后来随着玩家熟练度和套牌的增多,降到了50。经过我们的迭代,它变成了 65 以上。

未来,我们希望 AI 能够预测玩家的手牌和套牌。
随着卡片的更新,模型也需要手动更新,否则无法适应新的卡片。我们将使其自动化。
我们还将 AlphaZero 应用于其他回合制游戏,例如麻将和五子棋。

元宇宙数字产业服务平台
下载「陀螺科技」APP,获取前沿深度元宇宙讯息
110777025(手游交流群)
108587679(求职招聘群)
228523944(手游运营群)
128609517(手游发行群)










